
Henry Hong-Ning Dai
Hong Kong Baptist University
VDN: Variant-Depth Network for Motion Deblurring
Abstract
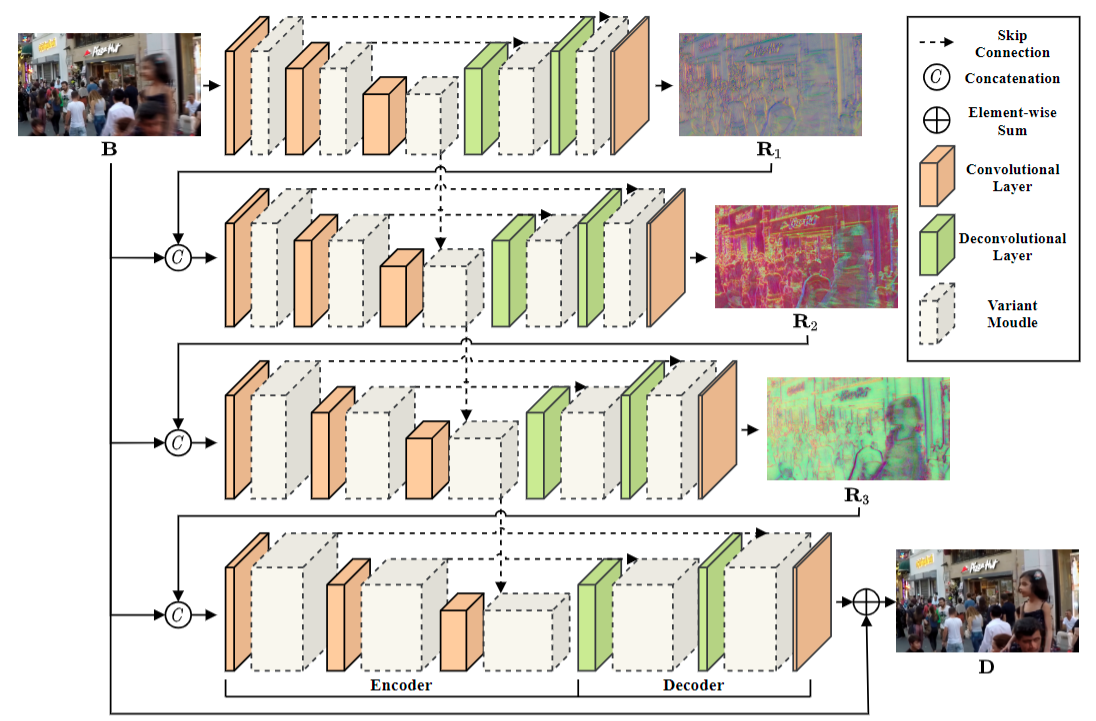
Motion deblurring is a challenging task in vision and graphics. Recent researches aim to deblur by using multiple sub-networks with multi-scale or multi-patch inputs. However, scaling or splitting operations on input images inevitably loses the spatial details of the images. Meanwhile, their models are usually complex and computationally expensive. To address these problems, we propose a novel variant-depth scheme. In particular, we utilize the multiple variant-depth sub-networks with scale-invariant inputs to combine into a variant-depth network (VDN). In our design, different levels of sub-networks accomplish progressive deblurring effects without transforming the inputs, thereby effectively reducing the computational complexity of the model. Extensive experiments have shown that our VDN outperforms the state-of-the-art motion deblurring methods while maintaining a lower computational cost. The source code is publicly available at: https://github.com/CaiGuoHS/VDN.
Bibtex
@article{https://doi.org/10.1002/cav.2066,
author = {Guo, Cai and Wang, Qian and Dai, Hong-Ning and Li, Ping},
title = {VDN: Variant-depth network for motion deblurring},
journal = {Computer Animation and Virtual Worlds},
volume = {n/a},
number = {n/a},
pages = {e2066},
keywords = {motion deblurring, scale-invariant input, variant-depth network},
doi = {https://doi.org/10.1002/cav.2066},
}