
Henry Hong-Ning Dai
Hong Kong Baptist University
TMVOS: Triplet Matching for Efficient Video Object Segmentation
Abstract:
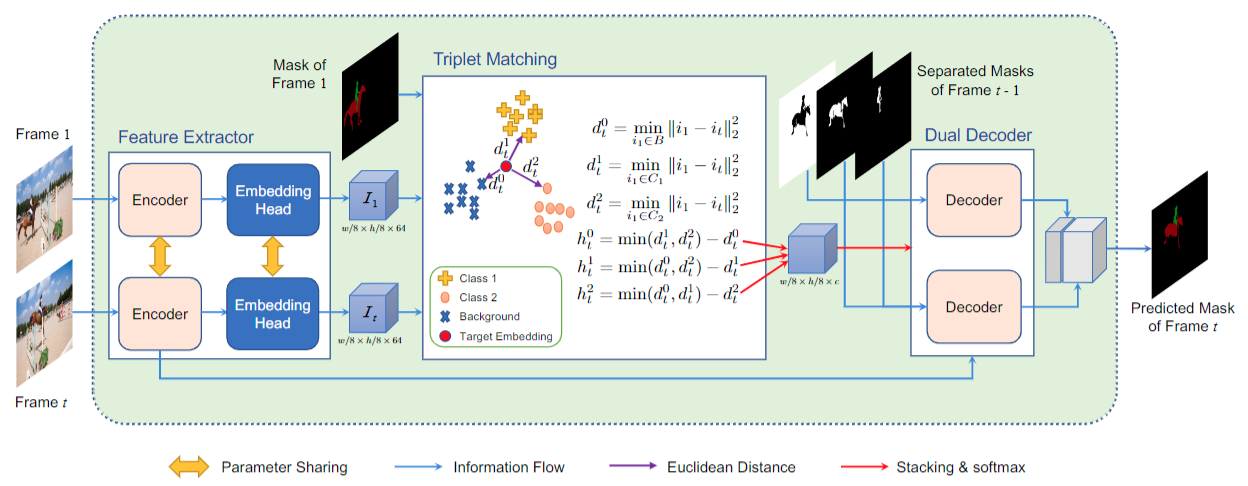
Video object segmentation (VOS) is a critical yet challenging task in video analysis. Recently, many pixel-level matching VOS methods have achieved an outstanding performance without significant time consumption in fine-tuning. However, most of these methods pay little attention to (i) matching background pixels and (ii) optimizing discriminable embeddings between classes. To address these issues, we propose a new end-to-end trainable method, namely Triplet Matching for efficient semi-supervised Video Object Segmentation (TMVOS). In particular, we devise a new triplet matching strategy that considers both the foreground and background matching and pulls the nearest negative embedding further than the nearest positive one for every anchor. As a result, this method implicitly enlarges the distances between embeddings of different classes and thereby generates accurate matching maps. Additionally, a dual decoder is applied for optimizing the final segmentation so that the model better fits the complex background and relatively simple targets. Extensive experiments demonstrate that the proposed method achieves superior performance in terms of accuracy and running-time compared with the state-of-the-art methods. The source code is available at: https://github.com/CVisionProcessing/TMVOS.
Bibtex
@article{LIU2022116779,
title = {TMVOS: Triplet Matching for Efficient Video Object Segmentation},
journal = {Signal Processing: Image Communication},
volume = {107},
pages = {116779},
year = {2022},
issn = {0923-5965},
doi = {https://doi.org/10.1016/j.image.2022.116779},
url = {https://www.sciencedirect.com/science/article/pii/S0923596522000947},
author = {Jiajia Liu and Hong-Ning Dai and Guoying Zhao and Bo Li and Tianqi Zhang},
}
Leave a Reply